NTU Multilingual Corpus (NTU-MC)
Documentation (draft)
The NTU Multilingual Corpus is a collection of parallel texts, with some sense tagged, some treebanked and some marked for sentiment.
The Structure of the Corpora
Monolingual Database Schema
- SQL Schema for the Indonesian Corpus
ind.db(not showing logs)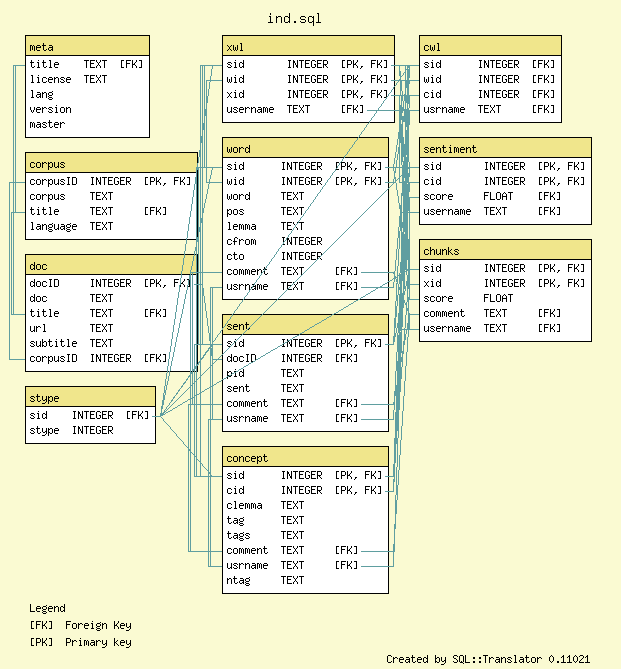
What was annotated when
An incomplete list
| Year | Class | Corpus | Lang | from-to | Comments |
|---|---|---|---|---|---|
| 2011 | hg2002 | Singapore Tourist Data | en | en>website | |
| 2012 | hg2002 | The Cathedral and the Bazaar | en | essay | |
| 2013 | hg2002 | SPEC (retag) | en | 10000, 10598 | |
| 2014 | hg2002 | DANC (retag) | en | 11000, 11607 | |
| 2015 | hg2002 | 蜘蛛の糸 [The Spider's Thread] | en | multilingual | |
| 2016 | hg8011 | REDH | en | 55657, 56209 | A-E |
| 2018 | hg8011 | SCAN | en | 50804, 51464 | |
| 2018 | hg2002 | HOUND | en | 45681, 46691 | A-B |
| 2019 | hg8011 | HOUND | en | 46692, 47487 | A-D (E two only) |
| 2019 | hg2002 | HOUND | en | 47488, 48504 | A-B (with sentiment) |
| 2020 | hg2002 | HOUND | en | 48505, 49505 | A-B (C one only) (with sentiment) |
| 2021 | hg8011 | FINA | en | 18525, 18935 | A-C (one D) (with sentiment) |
| 2021 | hg2002 | NAVA | en | 13147, 13968 | A-C to 13973 done by RA (with sentiment) |
| 2025 | DAS/[45]UJ2 | 110000, 110263 | War with the Newts (en) | A-D most of Chapter 1 |
|
| 2025 | DAS/[45]UJ2 | 110000, 110388 | War with the Newts (cs) | A-D Chapter 1 110361–110388 done by grad students |
2024 | DAS/4UJ2,5UJ2 | Válka s Mloky (twwtn) | cs | 110001, 110360 | A-D (with sentiment) |
| 2024 | DAS/4UJ2,5UJ2 | The War with the Newts (twwtn) | en | 110001, 110263 | A-D (with sentiment) |
References:
Canonical Citation:
Liling Tan and Francis Bond. 2012. Building and annotating the linguistically diverse NTU-MC (NTU-multilingual corpus). In International Journal of Asian Language Processing 22(4) pp 161–174.
Other References:
Francis Bond, Andrew Devadason, Melissa Rui Lin Teo and Luís Morgado da Costa (2021) Teaching Through Tagging — Interactive Lexical Semantics In Proceedings of the 11th Global Wordnet Conference (GWC 2021)
Francis Bond, Shan Wang, Eshley Huini Gao, Hazel Shuwen Mok, and Jeanette Yiwen Tan. 2013. Developing parallel sense-tagged corpora with wordnets. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse (LAW 2013). Sofia. pp 149–158.
Yu Jie Seah and Francis Bond. 2014. Annotation of Pronouns in a Multilingual Corpus of Mandarin Chinese, English and Japanese. In 10th Joint ACL - ISO Workshop on Interoperable Semantic Annotation Reykjavik.
Slav Petrov, Dipanjan Das, and Ryan McDonald. 2011. A universal part-of-speech tagset. arXiv preprint arXiv:1104.2086.
Shan Wang and Francis Bond. 2014. Building The Sense-Tagged Multilingual Parallel Corpus. In 9th Edition of the Language Resources and Evaluation Conference (LREC 2014), Reykjavik.
Francis Bond, Tomoko Ohkuma, Luis Morgado da Costa, Yasuhide Miura, Rachel Chen, Takayuki Kuribayashi, and Wenjie Wang (2016) A multilingual sentiment corpus for Chinese, English and Japanese. In Proceedings of the LREC 2016 Workshop “Emotion and Sentiment Analysis”, Portorož. pp 59–62
Contributors: Francis Bond, Luís Morgado da Costa, Tuan Anh Le, Michael Wayne Goodman and many more.
Especial thanks to the students and tutors of HG2002, HG8011, DAS/4UJ2 and DAS/5UJ2
Francis Bond <bond@ieee.org>
Division of Linguistics and Multilingual Studies
Nanyang Technological University
Level 3, Room 55, 14 Nanyang Drive, Singapore 637332
Tel: (+65) 6592 1568; Fax: (+65) 6794 6303 This is hosted at github: https://github.com/bond-lab/NTUMC